AIfred Intelligence
Example Conversations & Showcases
🔧 The Frankenstein MiniPC — 4 GPUs, 120 GB VRAM, 60W Idle
How a tiny AOOSTAR GEM 10 MiniPC ended up with 3x Tesla P40 (OCuLink) + RTX 8000 (USB4) across 4 eGPU adapters (all PCIe 3.0 x4). The full story: from the first OCuLink test to sawing fan grilles, fighting ReBAR, and running 235B models fully GPU-resident — with photos, cost breakdown, model configurations, and lessons learned.
View Full Setup🏆 Model Benchmark: "Dog vs Cat" Tribunal — 9 Models Compared
Same question, 9 different models, 18 sessions. "What is better, dog or cat?" in Tribunal mode (AIfred argues → Sokrates attacks → 2 rounds → Salomo verdict). Models range from Qwen3-Next-80B (3B active, ~31 tok/s) to Qwen3-235B (22B active, ~11 tok/s). Hardware: 3x Tesla P40 + RTX 8000 = ~115 GB VRAM, all models fully GPU-resident.
Key finding: Qwen3-Next-80B with only 3B active parameters matches the 235B model in debate quality (9.5/10) — at 3x the speed. GPT-OSS-120B is the speed champion (~50 tok/s) but scores only 6/10 on quality. And GLM-4.7-REAP at IQ3_XXS quantization... invented its own language.
Compare the debates yourself — click any model to read the full tribunal:
⭐ Quality Champions (9.5/10):
Qwen3-Next-80B (DE) 🔊 Qwen3-Next-80B (EN) Qwen3-Next-80B Thinking (DE) Qwen3-235B Q3 (DE) Qwen3-235B Q2 (EN)🏃 Speed Champion (~50 tok/s, 6/10 quality):
GPT-OSS-120B (DE) GPT-OSS-120B (EN)📊 Other Models:
Qwen3.5-122B (DE) MiniMax-M2.5 IQ3 (EN) MiniMax-M2.5 Q2 (EN) Qwen3-235B Q2 (DE)💀 The "Don't Do This" Award (2/10 — invented its own language):
GLM-4.7-REAP IQ3_XXS (DE/EN) — "geschten Fe Herrenhelmhen" Full Analysis (EN) Full Analysis (DE)Tensor Split Benchmark: Speed vs. Full Context
Does aggressive GPU placement matter? When running a 46.6 GB model across two unequal GPUs (RTX 8000 + Tesla P40), the tensor split ratio determines how much computation happens on the fast vs. slow GPU. This benchmark compares a balanced 2:1 split (full 262K context) against an aggressive 11:1 split (32K context, 92% on the fast GPU).
Measured through a real 6-turn AIfred tribunal debate ("Is water wet?") with 3 agents across 2 rounds. Results: 10–15% faster generation in Round 1, shrinking to ~4% in Round 2. Prompt processing is ~2% slower with aggressive split. Total wall-clock time: 10 seconds saved (113s vs 124s). Zero quality difference.
View Full Benchmark Raw Data (Markdown)🏆 Dog or Cat — Philosophical Multi-Agent Debate
Why this matters: Research shows multi-agent debate systems struggle with "rubber-stamping" (critics just agreeing), echo chambers, and information loss during synthesis. This debate demonstrates AIfred avoiding all these failure modes – with a local 30B model.
A trivial question evolves through four categorical phases: Character typology → Virtue ethics → Relationship theory → Meta-ethics of equality. Sokrates delivers real critique, Salomo synthesizes without information loss.
Konsens (DE) 🔊 Consensus (EN) 🔊 Tribunal (DE) Tribunal (EN) Konsens-Analyse (DE) Consensus Analysis (EN) Tribunal-Analyse (DE) Tribunal Analysis (EN)⚖️ Tribunal Mode — Error Handling Debate
Tribunal vs Auto-Consensus: In Tribunal mode, Sokrates acts as prosecutor (not coach). AIfred must DEFEND or REVISE – there's no [LGTM] voting. This A/B comparison shows how personality prompts affect the adversarial debate dynamic.
The question "Should every error be logged?" triggers a structured debate where AIfred defends his position against Sokrates' attacks, and Salomo delivers a final verdict. Compare WITH vs WITHOUT personality prompts to see the stylistic differences.
Full Debate WITH (DE) Full Debate WITH (EN) Full Debate WITHOUT (DE) Full Debate WITHOUT (EN) Analysis (DE) Analysis (EN)🔬 A/B Test: Code Review – WITH vs WITHOUT Personalities
Does personality affect quality? This side-by-side comparison shows the same "Should I split this Python function?" question answered with and without AIfred's Butler personality. Both use Auto-Consensus mode with [LGTM]/[WEITER] voting.
Result: Personality prompts add stylistic flair (British expressions, philosophical references) but the core technical analysis remains equivalent. This validates the 3-layer prompt architecture: Identity (who) + Personality (how, optional) + Task (what).
WITH Personality (DE) WITH Personality (EN) WITHOUT Personality (DE) WITHOUT Personality (EN)Chemistry: Balancing Combustion Equations
AIfred explains how to balance the combustion of ethanol step-by-step, with proper chemical notation rendered via mhchem. Features a coefficient table and verification of the law of conservation of mass.
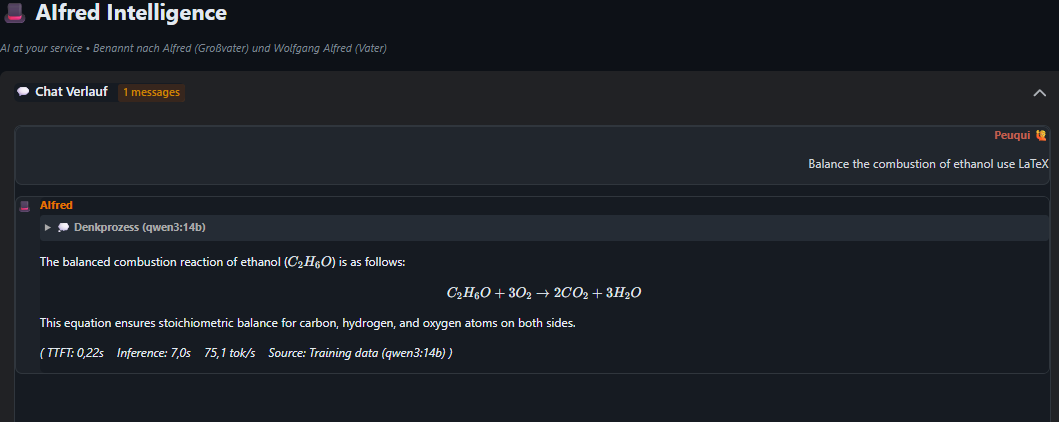 View Full Chat
View Full Chat
Physics: Schrodinger Equation for a Victorian Gentleman
"Explain the Schrodinger equation as if I'm a Victorian gentleman" - AIfred rises to the challenge with historical context, elegant LaTeX formulas, and analogies to a gentleman's drawing-room. A masterclass in making quantum mechanics accessible.
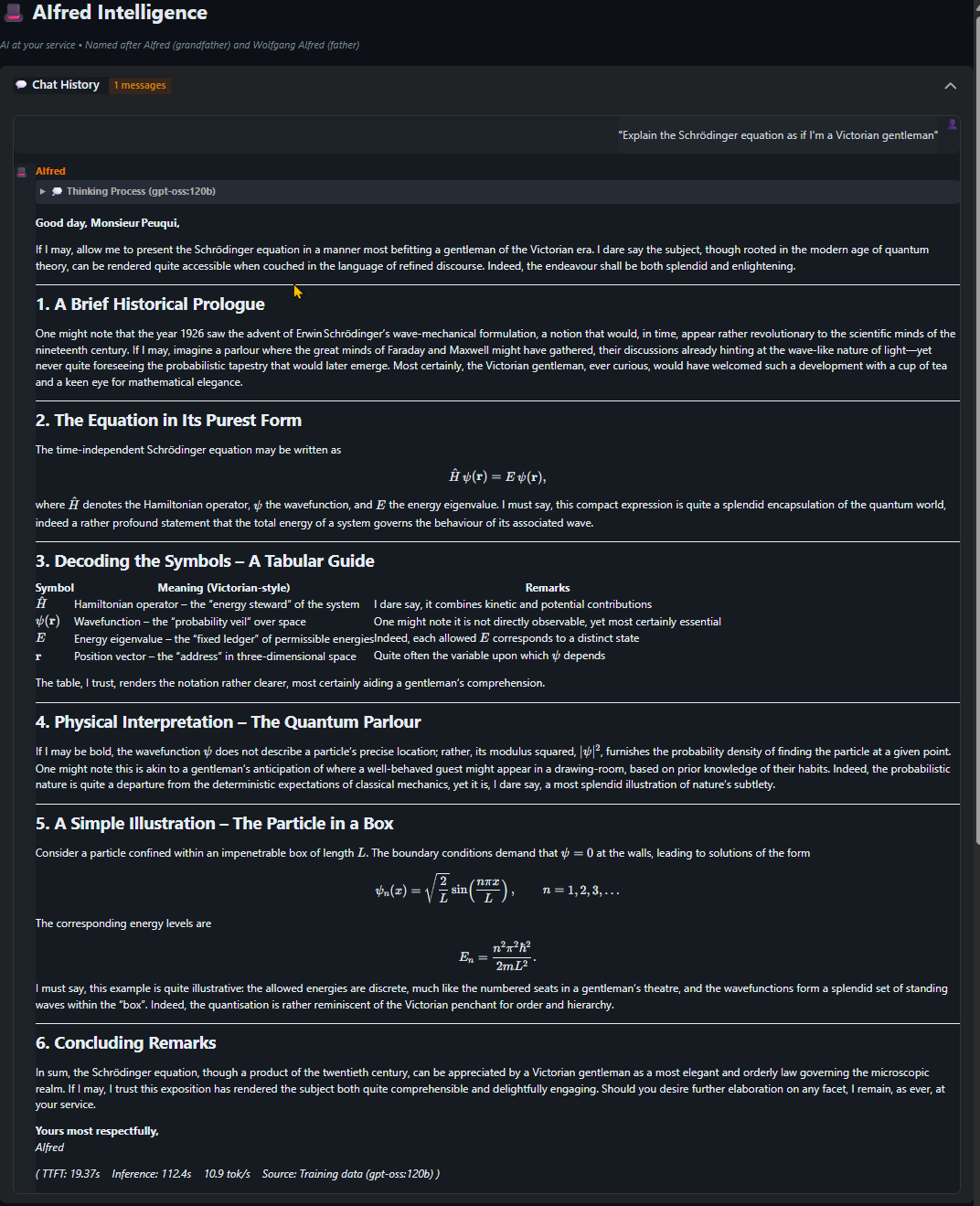 View Full Chat
View Full Chat
Python: Prime Number Calculator
A refined implementation of the Sieve of Eratosthenes algorithm, complete with type hints, docstrings, and Butler-style code comments. Shows AIfred's ability to write clean, well-documented code while maintaining his characteristic charm.
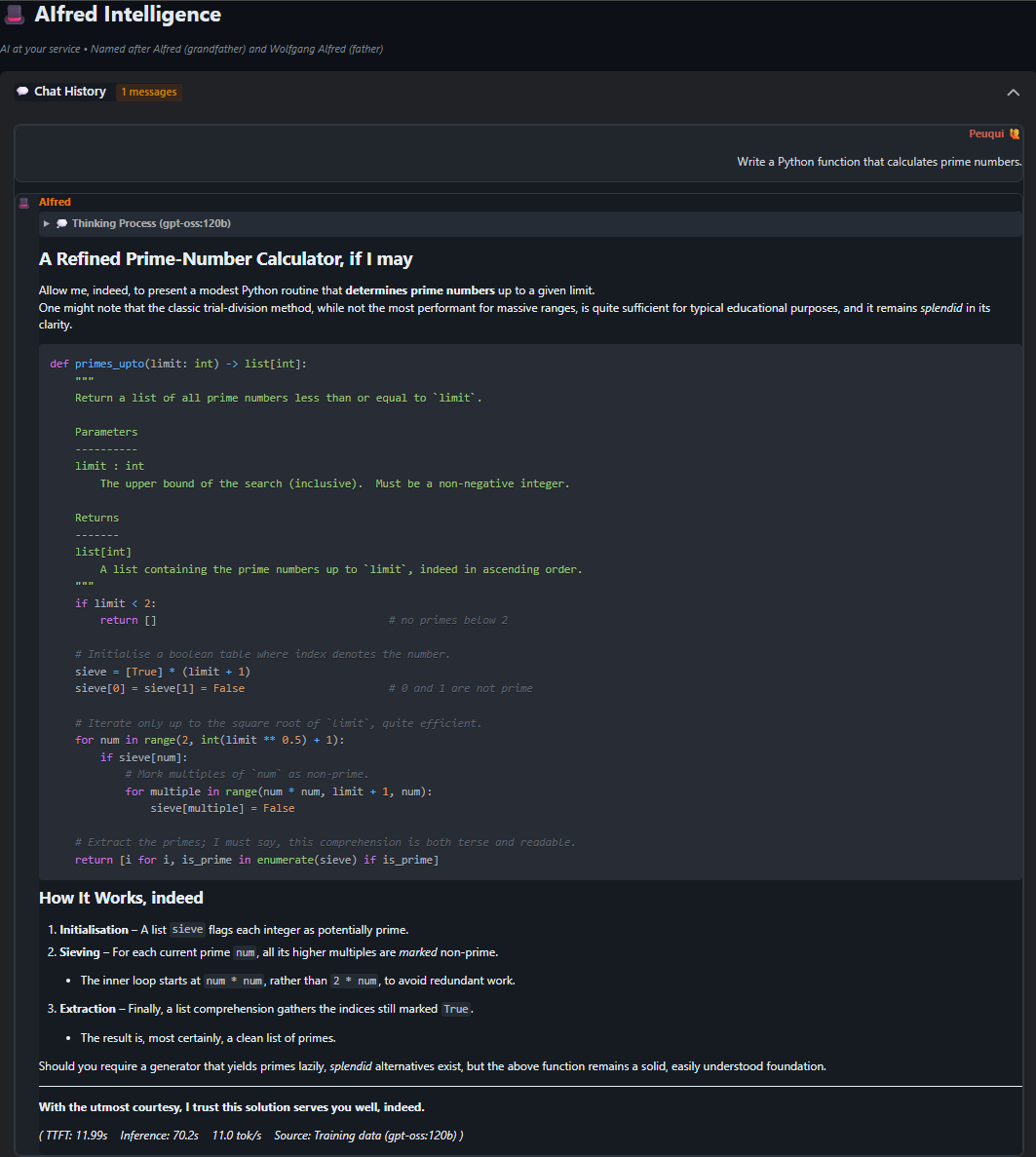 View Full Chat
View Full Chat
Medical Research: Spinal Anesthesia Guidelines
A complex medical query about spinal anesthesia in patients with myasthenia gravis. AIfred automatically searches medical literature, synthesizes findings from multiple sources, and provides a cautious, well-referenced answer with proper citations.
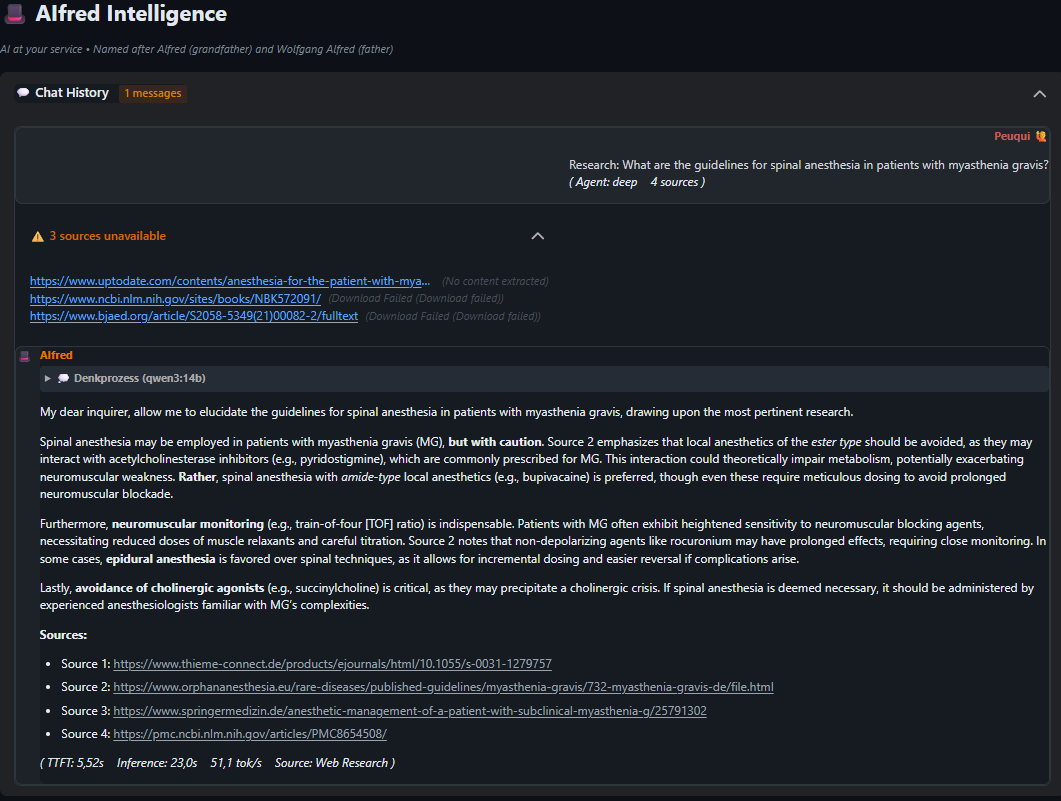 View Full Chat
View Full Chat